One of my mathematics lecturers once invited us to solve a problem that has fascinated me ever since. If you create a digital sound clip by recording your own voice, how can you transform that to mimic the celebrated Norwegian weather forecaster Vidar Theisen?
For those of us never having heard about dear Mr. Theisen, or even wasn’t born before he passed away, you can watch one of his daily NRK weather forecasts below.
It is pretty obvious that Mr. Theisen had a very distinct way of talking. A voice of slow tempo accompanied by a monotonic pitch. Nobody, at least at that time, would be unsure who you pretended to be if you slowly and flat-voiced said something about the weather at Spitsbergen.
The lecturer also happened to be my adviser, and his name is Prof. Hans Munthe-Kaas. Hans is a very good man, and he has opened many doors for students that has knocked on his door. He is on my list of personal relationships I could not have been without.
To get the wheels rolling in his students heads, Mr. Munthe-Kaas outlined several incorrect strategies you could try to begin with: to slow things down by a factor two, try to repeat the digital samples one-by-one so that the net duration will be doubled. Or even better, try to interpolate?
It turns out that both strategies actually works in terms of doubling the duration, but has the inevitable side effect of also shifting down the pitch of audio signals. It is analogous to slowing down the rotational speed of a record player: it obviously decreases the tempo of the sound, but the tone will also be darker. If you happen to own a record player, you are probably nodding affirmative at this point. In other words, we approach Mr. Theisen in terms of tempo, but not by tone. For pure sinusoidal waves, what we want is to extend the number of periods rather than increasing the length of one period.
Virtually, the tempo and pitch of a tune is inseparable. If you change the tempo, the pitch will also change. The figure on the right illustrates the concept: modifications can seemingly only be done along the green diagonal line.
Until the mid 60s, this was accepted as the truth. Then suddenly a paper disturbed the community; two bright guys named Flanagan and Golden solved the problem in the context of telecommunication. Thanks to it, we can separate the two parameters. Controlling the Theisen tempo independently of the tone is now easy. And the invention’s name? The Phase Vocoder.
According to the theory, and some years of trial and error for my part, if what you want is to change the tempo of a signal by a factor Pt/Qt, and shift the pitch by a factor Pp/Qp, all you have to do is the following:
Linearly interpolate the magnitude of the STFT by a factor Pt/Qt*Qp/Pp across the time dimension.
Go over the phase of the STFT and make sure that the partial time derivative across the time dimension is preserved.
Transform the modified STFT back into the time domain
Re-sample the resulting waveform by a factor Qp/Pp to get the final waveform.
We definitely need some test data to try this out. I have recorded my own voice saying the following in Norwegian:
“Som vi ser har det blitt kuldegrader over omtrent hele landet”.
Translated to English this corresponds to something like: “As you can see, we now have temperatures below zero degrees across the whole country”. You can listen to the original sound clip in the player below.
This Matlab code implements the Theisen Transform following the step-by-step Phase Vocoder recipe above:
functiony = theisen(x)%% Geir K. Nilsen, 2006% geir.kjetil.nilsen@gmail.com%
Ns = length(x);
Nw = 1024; % Window width
hop = Nw/4; % Overlap width
Pt = 2;
Qt = 5;
Pp = 5;
Qp = 6;
r = Pt/Qt * Qp / Pp; % Tempo-pitch shift factor
win = hann(Nw, 'periodic');
Nf = floor((Ns + hop - Nw) / hop);
fframe = zeros(Nw,Nf);
pframe = zeros(Nw,Nf);
% Step 1: STFT
c = 1;
fori = 0:hop:((Nf-1)*hop);
fframe(:,c) = 2/3*fft(x(1+i:i+Nw).*win');
c = c + 1;
end;
% Step 2 & 3: Linear interpolation & phase preservation
phase = angle(fframe(:,1));
c = 1;
x = [fframe zeros(size(fframe, 1),1)];
fori = 0:r:Nf-1;
x1 = x(:,floor(i)+1);
x2 = x(:,floor(i)+2);
scale = i - floor(i);
mag = (1-scale)*abs(x1) + scale*(abs(x2));
pframe(:,c) = mag .* exp(j*phase);
c = c + 1;
phase_adv = angle(x2) - angle(x1);
% Accumulate the phase
phase = phase + phase_adv;
end;
% Step 4: synthesize frames to get back waveform. Known as the Inverse% Short Time Fourier Transform.
c = 1;
Nf = size(pframe,2);
Ns = Nf*hop - hop + Nw;
y = zeros(1,Ns);
fori = 0:hop:((Nf-1)*hop);
pframe(:,c) = real(ifft(pframe(:,c)));
y(1+i:i+Nw) = y(1+i:i+Nw) + pframe(:,c)'.*win';
c = c + 1;
end;
% Step 5: finally resample the waveform to adjust according% to the pitch shift factor.
y = resample(y, Pp, Qp);
When applied to the original recording, the result is quite impressing. Listen to the modified sound clip below and judge yourself.
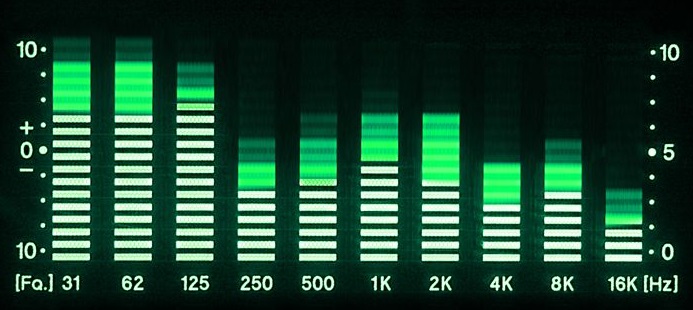
As a kid I was very fascinated by a particular type of electronic devices known as equalizers. These devices are used to adjust the balance between frequency components of electronic signals, and has a widespread application in audio engineering.
As I grew up the fascination continued, but shifted from wanting to own one — into wanting to build one — into wanting to code one.
In this article I will explain how you can code your own audio equalizer, enabling you to integrate your own variant in your own projects. Let us start with some background information and basic theory.
When you use the volume knob to pump up the volume on your stereo, it will boost all the frequency components of the audio by roughly the same amount. The bass and treble controls on some stereos take this concept one step further; they divide the whole frequency range into two parts — where the bass knob controls the volume in the lower frequency range and the treble knob controls the volume in the upper frequency range.
Now, with an audio equalizer, you have the possibility to adjust the volume on any given number of individual frequency ranges, separately.
Physically, the front panel of an equalizer device typically consists of a collection of slider knobs, each corresponding to a given frequency range — or more specifically — to a given center frequency. The term center frequency refers to the mid point of the frequency range the slider knob controls.
By arranging the sliders in increasing center frequency order, the combined positions of the individual sliders will represent the overall frequency response of the equalizer. This is where it gets interesting, because the horizontal position of the slider now represents frequency, and the vertical position represents the response modification you wish to impose on that frequency. In other words, you can “draw” your desired frequency response by arranging the sliders accordingly.
Theory of Parametric Equalizers
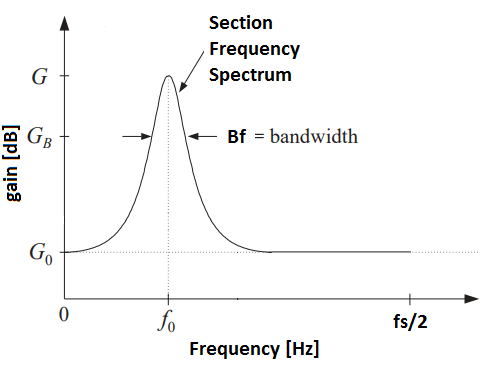
An additional degree of freedom arises when the center frequency per slider also is adjustable. This is exactly what a parametric equalizer is: it lets the user specify a number of sections (think of section here as a slider), each with a frequency response adjustable by the following parameters: center frequency (f0), bandwidth (Bf), bandwidth gain (GB), reference gain (G0) and boost/cut gain (G):
The center frequency (f0) represents the mid-point of the section’s frequency range and is given in Hertz [Hz].
The bandwidth (Bf) represents the width of the section across frequency and is measured in Hertz [Hz]. A low bandwidth corresponds to a narrow frequency range meaning that the section will concentrate its operation to only the frequencies close to the center frequency. On the other hand, a high bandwidth yields a section of wide frequency range — affecting a broader range of frequencies surrounding the center frequency.
The bandwidth gain (GB) is given in decibels [dB] and represents the level at which the bandwidth is measured. That is, to have a meaningful measure of bandwidth, we must define the level at which it is measured. See Figure 1.
The reference gain (G0) is given in decibels [dB] and simply represents the level of the section’s offset. See Figure 1.
The boost/cut gain (G) is given in decibels [dB] and prescribes the effect imposed on the audio loudness for the section’s frequency range. A boost/cut level of 0 dB corresponds to unity (no operation), whereas negative numbers corresponds to cut (volume down) and positive numbers to boost (volume up).
Figure 1: Section Frequency Spectrum
A section is really just a filter — in our case a digital audio filter with the parameters corresponding to the elements in the list above.
Implementation in Matlab
The abstraction now is the following: a parametric audio equalizer is nothing else than a list of digital audio filters acting on the input signal to produce an output signal with the desired balance between frequency components.
This means that the smallest building block we need to create is a digital audio filter. Without going deep into the field of digital filter design, I will make it easy for you and jump straight to the crucial equation required:
Equation 1
a0*y(n) = b0*x(n) + b1*x(n-1) + b2*x(n-2)
- a1*y(n-1) - a2*y(n-2), for n = 0, 1, 2, ...
In equation 1, x(n) represents the input signal, y(n) the output signal, a0, a1 and a2, are the feedback filter coefficients, and b0, b1 and b2, are the feedforward filter coefficients.
To calculate the filtered output signal, y(n), all you have to do is to run the input signal, x(n), through the recurrence relation given by equation 1. In Matlab, equation 1 corresponds to the filter function. We will come back to it shortly, but first we need to get hold of the filter coefficients (a0, a1, a2, b0, b1 and b2).
At this point, you can read Orfanidis’ paper and try to grasp the underlying mathematics, but I will make it easy for you. Firstly, we define the sampling rate of the input signal x(n) as fs, and secondly, by using the section parameters defined above, the corresponding filter coefficients can be calculated by
Note that beta in equation 2is just used as an intermediate variable to simplify the appearance of equations 3 through 8. Also note that tan() and cos() represents the tangens and cosine functions, respectively, pi represents 3.1415…, and sqrt() is the square root.
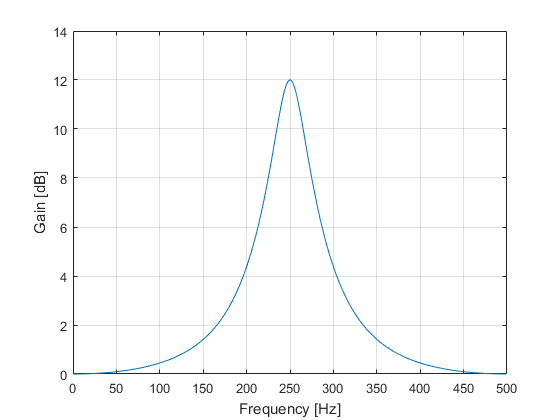
As an example, if we define the following section parameters:
It means that we will have a section operating at a 1 kHz sampling rate with a center frequency of 250 Hz, bandwidth of 40 Hz, bandwidth gain of 9 dB, reference gain of 0 dB and boost gain of 12 dB. See Figure 2 for the frequency response (spectrum) of the section.
Figure 2: Example Section Frequency Spectrum
Let’s say we have defined a list of many sections. How do we combine all the sections together so we can see the overall result? The following Matlab script illustrates the concept by setting up a 4-section parametric equalizer.
% Parametric Equalizer by Geir K. Nilsen (2017)
clear all;
fs = 1000; % Sampling frequency [Hz]
S = 4; % Number of sections
Bf = [5 5 5 5]; % Bandwidth [Hz]
GB = [9 9 9 9]; % Bandwidth gain (level at which the bandwidth is measured) [dB]
G0 = [0 0 0 0]; % Reference gain @ DC [dB]
G = [8 10 12 14]; % Boost/cut gain [dB]
f0 = [200 250 300 350]; % Center freqency [Hz]
h = [1; zeros(1023,1)]; % ..for impulse response
b = zeros(S,3); % ..for feedforward filter coefficients
a = zeros(S,3); % ..for feedbackward filter coefficients
for s = 1:S;
% Equation 2
beta = tan(Bf(s)/2 * pi / (fs / 2)) * sqrt(abs((10^(GB(s)/20))^2 - (10^(G0(s)/20))^2)) / sqrt(abs(10^(G(s)/20)^2 - (10^(GB(s)/20))^2));
% Equation 3 through 5
b(s,:) = [(10^(G0(s)/20) + 10^(G(s)/20)*beta), -2*10^(G0(s)/20)*cos(f0(s)*pi/(fs/2)), (10^(G0(s)/20) - 10^(G(s)/20)*beta)] / (1+beta);
% Equation 6 through 8
a(s,:) = [1, -2*cos(f0(s)*pi/(fs/2))/(1+beta), (1-beta)/(1+beta)];
% apply equation 1 recursively per section.
h = filter(b(s,:), a(s,:), h);
end;
% Plot the frequency spectrum of the combined section impulse response h
H = db(abs(fft(h)));
H = H(1:length(H)/2);
f = (0:length(H)-1)/length(H)*fs/2;
plot(f,H)
axis([0 fs/2 0 20])
xlabel('Frequency [Hz]');
ylabel('Gain [dB]');
grid on
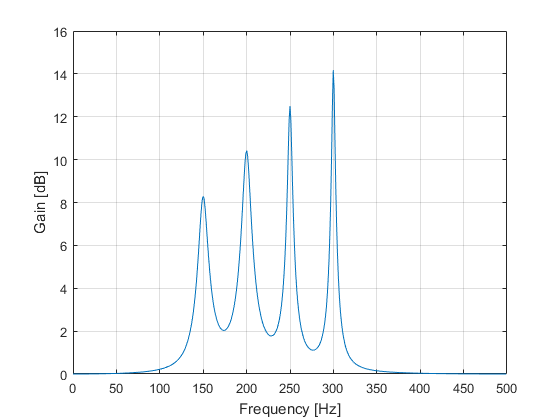
The key to combining the sections is to run the input signal through the sections in a cascaded fashion: the output signal of the first section is fed as input to the next section, and so on. In the script above, the input signal is set to the delta function, so that the output of the first section yields its impulse response — which in turn is fed as the input to the next section, and so on. The final output of the last section is therefore the combined (total) impulse response of all the sections, i.e. the impulse response of the parametric equalizer.
The FFT is then applied on the overall impulse response to calculate the frequency response, which finally is used to produce the frequency spectrum of the equalizer shown in Figure 3.
Figure 3: Parametric Equalizer Frequency Spectrum
The next section of this article will address how to make the step from the Matlab implementation above to a practical implementation in C#. Specifically, I will address:
How to run the equalizer in real-time, i.e. how to apply it in a system where only few samples of the actual input signal is available at the same time — and furthermore ensure that the combined output signals will be continuous (no hiccups).
How to object orientate the needed parts of the implementation.
Real-time considerations
Consider equation 1 by evaluating it for n=0,1,2, and you will notice that some of the indices on the right hand side of the equation will be negative. These terms with negative index correspond to the recurrence relation’s initial conditions. If we consider the recurrence relation as a one-go operation, it is safe to set those terms to zero. But what if we have a real system sampling a microphone at a rate of fs=1000 Hz, and where the input signal x(n) is made available in a finite length buffer of size 1000 samples — updated by the system once every second?
To ensure that the combined output signals will be continuous, the initial conditions must be set based on the previous states of the recurrence relation. In other words, the recurrence relation implementation must have some memory of its previous states. Specifically, it means that at the end of the function implementing the recurrence relation, one must store the two last samples of the current output and input signals. When the next iteration starts, it will use those values as the initial conditions y(-1), y(-2), x(-1) and x(-2).
A practical C# Implementation
I will now give a practical implementation in C#. It consists of three classes
Filter.cs — Implements the recurrence relation given in equation 1. And yes, it is made to deal gracefully with the initial condition problem stated in the previous section.
Section.cs — Implements a section as described by the parameters listed previously.
namespace ParametricEqualizer
{
public class ParametricEqualizer
{
private int numberOfSections;
private List section;
private double[] G0;
private double[] G;
private double[] GB;
private double[] f0;
private double[] Bf;
public ParametricEqualizer(int numberOfSections, int fs, double[] f0, double[] Bf, double[] GB, double[] G0, double[] G)
{
this.numberOfSections = numberOfSections;
this.G0 = G0;
this.G = G;
this.GB = GB;
this.f0 = f0;
this.Bf = Bf;
section = new List();
for (int sectionNumber = 0; sectionNumber < numberOfSections; sectionNumber++)
{
section.Add(new Section(f0[sectionNumber], Bf[sectionNumber], GB[sectionNumber], G0[sectionNumber], G[sectionNumber], fs));
}
}
public void run(List x, ref List y)
{
for (int sectionNumber = 0; sectionNumber < numberOfSections; sectionNumber++)
{
section[sectionNumber].run(x, out y);
x = y; // next section
}
}
}
}
Usage Example
Let’s conclude the article by an example where we create a ParamtricEqualizer object and applies it on some input data. The following snippet will setup the equivalent 4-section equalizer as in the Matlab implementation above.
double[] x = new double[] { 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0}; // input signal (delta function example)
List y = new List(); // output signal
ParametricEqualizer.ParametricEqualizer peq = new ParametricEqualizer.ParametricEqualizer(4, 1000, new double[] { 200, 250, 300, 350 }, new double[] { 5, 5, 5, 5 }, new double[] { 9, 9, 9, 9 }, new double[] {0, 0, 0, 0}, new double[] {8, 10, 12, 14});
peq.run(x.ToList(), ref y);
I was scanning through an old hard drive when I came across it. A large file of assembly code I had written many years ago. Its code section was tiny, but its data section huge.
It was my good old Linux audio player where the raw audio data was baked into the source itself. Or the other way around, a raw audio file with a built-in player. An interesting but sort of pathetic attempt to an executable audio file with no form of compression.
Skipping most of the data section (i.e. …), it looks like this:
;
; Minimalistic (or maximalistic?) Linux OSS audio player
; by Geir K. Nilsen (2006)
; geir.kjetil.nilsen@gmail.com
;
SECTION .data
dsp dd "/dev/dsp", 0
on dd 1
fmt dd 0x00000010
sfr dd 44100
buf db 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,...
SECTION .text
global _start
_start:
mov eax, 5 ; Open DSP for read/write. System call
mov ebx, dsp ; no 5. Set pointer to dsp string
mov ecx, 02 ; O_RDWR is defined to be 2 according
int 0x80 ; to asm/fcntl.h
; File descriptor number now in eax.
push eax ; Take four copies for later system
push eax ; calls.
push eax
push eax
push eax
; OSS configuration
mov eax, 54 ; Set stereo, syscall ioctl is54
pop ebx
mov ecx, 0xC0045003 ; See man ioctl_list,
mov edx, on ; SNDCTL_DSP_STEREO
int 0x80
mov eax, 54 ; Setformat, 16bitlittleendian
pop ebx ; Format of buf is 8 bit, but 2-by-2
mov ecx, 0xC0045005 ; samples are multiplexed to 16 bits
mov edx, fmt ; stereo samples.
int 0x80
mov eax, 54 ; Set sampling frequency, 44100 Hz.
pop ebx
mov ecx, 0xC0045002
mov edx, sfr
int0x80
mov eax, 4 ; Prepareand write to DSP.
pop ebx
mov ecx, buf
mov edx, 0x000AC440int0x80 ; ..and play!
mov eax, 6 ; Close DSP. Sys callnumber6.
pop ebx
int0x80
mov eax, 1 ; Exit
mov ebx, 0
int 0x80
I tried to recall what audio could be included in the file. Must boot up Linux to find the answer. Then assemble the file, and execute it. But I only have Windows on my laptop these days, so need to install it. This calls for WMware, or will it work under Cygwin? Heck, is OSS still supported by the kernel? And what assembler to use, Nasm? Or was it gas back then?
Wait, I will just parse and extract buf instead, the long string of comma-separated numbers. All the required information is provided by my comments: 16-bits samples, little endian, stereo (2 channels), sampling rate of 44100 Hz. Must be an easy job in Matlab using fscanf() and sound(). On the other hand, to recognize what will be played can turn out to be tricky. Given the file size and sampling rate, not so many audible seconds there will be. But Shazam can probably help, since I am quite sure it is a song.
I decided to challenge my team instead. They can solve my riddle outside normal working hours. Good learning for them it might be. Speaking about killing two birds with one stone.
Later the same night, me having forgotten all about the audio riddle, senior software engineer Øyvind Rørtveit sent out an e-mail containing just a short and incomprehensible sentence – “Blame it on me”. Yikes, what has he done now? I Will never blame it on you buddy, but come on, why so tight-lipped?
Øyvind is one of the best programmers I have ever known. He is like Mel,
but also with the ability to understand and translate complex mathematical concepts into working code. More about him sometime later.
I grabbed the phone and called him. I asked what was going on, and he said, “Isn’t it correct?” — “Correct what?”, I responded. “The riddle”, he said with a disappointed voice. But I was confused and struggled to find the harmony in all this.
It turned out that the brilliant riddle-maker had completely lost the solution to his own riddle, and that Øyvind had to convince him of the answer. “Yes! You are right!” — “But no, I know the answer and it isn’t this”, I said with a hint of despair, simultaneously not able to tell him the actual solution.
But he was right, and after listening to the whole song after we hung up, it again reminded me why I had chosen this song as the solution to the riddle.